
آنچه در این مقاله میخوانید
بهینهترین روش خواندن فایل در Node.js
۲۶ اردیبهشت ۱۴۰۰
خلاصه کنید:



ممکن در موارد مختلفی مانند ثبت خطاهای برنامه در فایل Log یا بررسی عملکرد برنامه نیاز باشد تا با فایلها کار کنید. صرف نظر از دلیل شما برای کار با فایلها، خواندن یک فایل در برنامهی Node.js بسیار ساده و آسان است اما اگر اندازهی فایل مورد نظر بیشتر از مقدار RAM سرور باشد یا حتی محدودیتهایی بر روی سرور شما اعمال شده باشد با مشکل روبرو خواهید شد بنابراین باید بهدنبال راه حلی بهینهتر برای خواندن فایلها در Node.js باشید.
حال در این مقاله تصمیم داریم بهینهترین روش برای خواندن فایلها در Node.js را با بررسی راه حلهای زیر پیدا کنیم:
fs.readFileSyncfs.createReadStreamfs.read

آنچه در این مقاله میخوانید:
- بررسی نمودارها
- نحوه خواندن فایلها در Node.js
- خواندن فایلها در Node.js با fs.createReadStream
- کنترل بیشتر با استفاده از fs.read
بررسی نمودارها
نمودار زیر از برنامهی پیادهسازی شدهی Node.js که در یک Docker container اجرا شده و مسئولیت آن خواندن یک فایل یک گیگابایتی بهصورت Chunkهای ده مگابایتی بوده، بهدست آمده است. همچنین توجه داشته باشید که مقدار memory در نمودار زیر حاصل جمع memory استفاده شده توسط Node.js و تمام فرایندهای Docker container است.
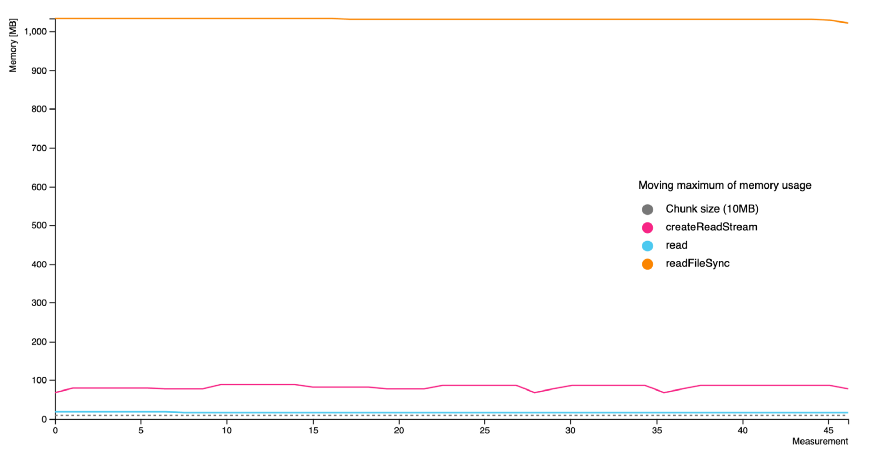
همانطور که مشاهده میکنید متد fs.readFileSync بیش از یک گیگابایت از حافظه را اشغال میکند. پس از آن میزان حافظهی استفاده شده توسط متد fs.createReadStream را مشاهده میکنید و درنهایت میزان حافظهی استفاده شده توسط متد fs.read وجود دارد که حدودا دو برابر اندازهی هر Chunk از حافظهی سرور استفاده میکند.
نحوه خواندن فایلها در Node.js
متد fs.readFileSync یا متد Asynchronous آن یعنی fs.readFile از اولین انتخابهای توسعهدهندگان برای خواندن فایلها در Node.js است زیرا با نوشتن چند خط کد بسیار ساده و یک حلقهی for به تمام دادههای موجود در فایل دسترسی پیدا میکنند و با پیمایش آن میتوانند کارهای مختلفی انجام دهند:
const CHUNK_SIZE = 10000000; // 10MB
const data = fs.readFileSync('./file');
for (let bytesRead = 0; bytesRead < data.length; bytesRead = bytesRead + CHUNK_SIZE) {
// do something with data
}اما با مشاهدهی نمودارهای بخش قبل متوجه میشوید که این راه حل مقدار زیادی از RAM را اشغال میکند زیرا در این روش تمام دادههای فایل در متغیر data ذخیره میشود بنابراین جای تعجب نیست که برای یک فایل یک گیگابایتی بیش از یک گیگابایت از RAM را اشغال کند.
خواندن فایلها در Node.js با fs.createReadStream
استفاده از متد fs.createReadStream بهسادگی متد fs.readFile است اما این متد مقدار stream را return میکند بنابراین شما به یک فرایند پردازشی دیگر نیاز خواهید داشت تا به دادههای واقعی دسترسی پیدا کنید و ما در مثال زیر از یک حلقهی for await استفاده کردهایم که پیمایش آرایه را برای ما آسانتر میکند:
const CHUNK_SIZE = 10000000; // 10MB
async function start() {
const stream = fs.createReadStream('./file', { highWaterMark: CHUNK_SIZE });
for await (const data of stream) {
// do something with data
}
}
start();متغیر highWaterMark باعث میشود که فقط بهاندازهی تعداد بایتهای تعریف شده از فایل مورد نظر خوانده شود و به این شکل شاهد کارکرد بهینهتر حافظه خواهیم بود زیرا اندازهی محدودی از دادهها در حافظه نگهداری میشود.
کنترل بیشتر با استفاده از fs.read
این روش کمی پیچیدهتر از دو روش قبلی است بااینحال کمترین میزان استفاده از RAM را در این روش شاهد هستیم اما قبل از بررسی جزئیات باید بدانید که shared buffer چیست؟
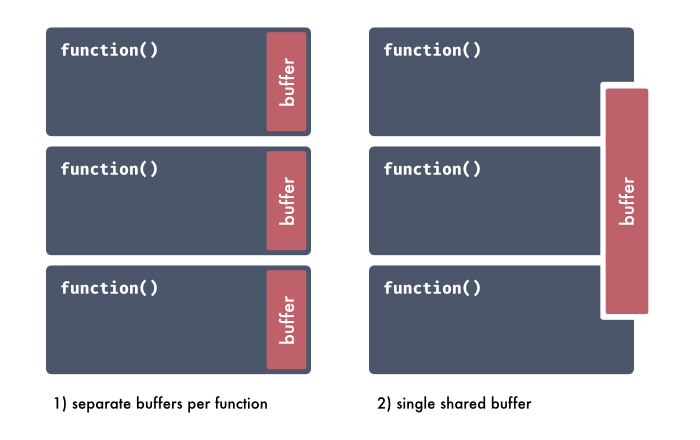
shared buffer یک متغیر passed by refrence است و بهجای ایجاد یک buffer جدید در هر فانکشن، یک buffer واحد در ابتدای برنامه ایجاد میشود. در نمودار زیر میتوانید مقایسهی بین دو برنامهی مختلف را مشاهده کنید که در یکی از shared buffer استفاده شده است.
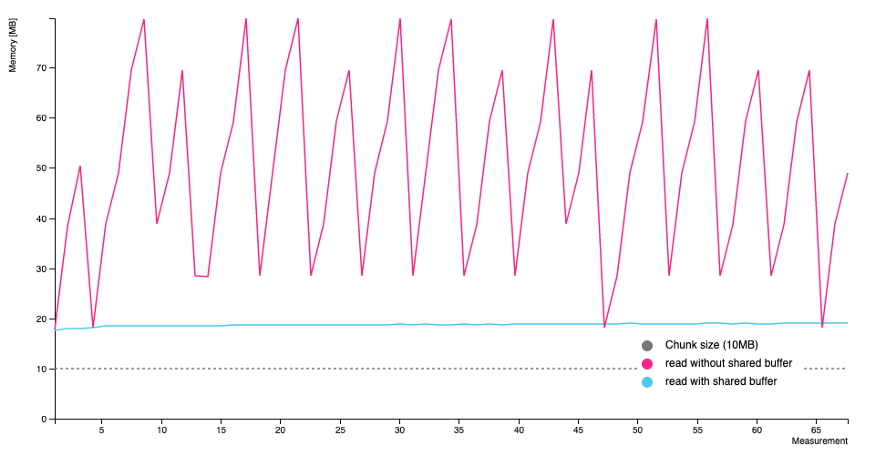
همانطور که مشاهده میکنید با استفاده از shared buffer شاهد استفادهی بهینهتر حافظه هستیم و علاوهبرآن سازگاری بیشتری در برنامهی ما بهوجود خواهد آمد.
حال که مفهوم shared buffer را متوجه شدید بهسراغ پیادهسازی برنامه میرویم. در مرحلهی اول باید یک فانکشن با نام readBytes توسعه دهیم که یک Promise از fs.read را return میکند:
function readBytes(fd, sharedBuffer) {
return new Promise((resolve, reject) => {
fs.read(
fd,
sharedBuffer,
0,
sharedBuffer.length,
null,
(err) => {
if (err) { return reject(err); }
resolve();
}
);
});
}به دلیل اینکه نمیخواهیم به ریزجزئیات بپردازیم توصیه میشود که برای درک کدهای بالا به مستندات fs.read در سایت Node.js مراجعه کنید.
در مرحلهی بعد یک asynchronous generator با نام generateChunks را توسعه میدهیم:
async function* generateChunks(filePath, size) {
const sharedBuffer = Buffer.alloc(size);
const stats = fs.statSync(filePath); // file details
const fd = fs.openSync(filePath); // file descriptor
let bytesRead = 0; // how many bytes were read
let end = size;
for (let i = 0; i < Math.ceil(stats.size / size); i++) {
await readBytes(fd, sharedBuffer);
bytesRead = (i + 1) * size;
if (bytesRead > stats.size) {
// When we reach the end of file,
// we have to calculate how many bytes were actually read
end = size - (bytesRead - stats.size);
}
yield sharedBuffer.slice(0, end);
}
}درنهایت دادهها را بهکمک حلقهی for پردازش خواهیم کرد:
const CHUNK_SIZE = 10000000; // 10MB
async function main() {
for await (const chunk of generateChunks('./file', CHUNK_SIZE)) {
// do someting with data
}
}
main();البته باید بدانید که استفاده از این روش کمی ریسک بههمراه دارد و امکان دارد Data leak یا Data malformation رخ دهد بنابراین باید در استفاده از این روش محتاط باشید.
آموزش نصب Nodejs روی ویندوز را در مقاله زیر بخوانید.
نصب Nodejs روی ویندوز
جمع بندی
در این مقاله با سه روش متداول برای خواندن فایلها در Node.js آشنا شدیم: fs.readFileSync، fs.createReadStream و fs.read. در حالی که readFileSync سادهترین روش برای توسعهدهندگان است، اما بهدلیل بارگذاری کل فایل در حافظه، میتواند مصرف RAM بسیار بالایی داشته باشد. در مقابل، createReadStream با استفاده از Stream و کنترل اندازهی خوانش (با کمک highWaterMark) مصرف حافظه را بهینهتر میکند و در اکثر کاربردها یک انتخاب متعادل و امن بهشمار میرود.
منبع: https://betterprogramming.pub/a-memory-friendly-way-of-reading-files-in-node-js-a45ad0cc7bb6
