
آنچه در این مقاله میخوانید
Apache Cassandra چیست؟
۲۹ تیر ۱۳۹۹
خلاصه کنید:



مدیریت حجم عظیمی از دادههای توزیعشده، همواره یکی از چالشهای اصلی در سیستمهای بزرگ و مقیاسپذیر بوده است. زمانی که عملکرد، دسترسپذیری و تحمل خطا به اولویتهای اصلی یک معماری تبدیل میشوند، ابزارهای سنتی پاسخگو نیستند. Cassandra پاسخی نوآورانه به همین نیاز است؛ یک سیستم مدیریت دیتابیس NoSQL که با معماری توزیعشده و مدل دادهای مبتنی بر ستونها، امکان ذخیرهسازی، پردازش و دسترسی سریع به دادهها را در مقیاس بالا فراهم میکند. توسعهی اولیهی آن در دل زیرساخت فنی Facebook شکل گرفت، اما امروز به یکی از ابزارهای کلیدی بسیاری از شرکتهای بزرگ دنیا برای مدیریت دادههای گسترده و همیشه در دسترس تبدیل شده است.
در ادامه خواهید خواند:
- معرفی Apache Cassandra
- قابلیتهای دیتابیس Cassandra
- جمع بندی

معرفی Apache Cassandra
Cassandra یک سیستم متنباز و توزیع شده برای مدیریت دیتابیسها است که دادهها را در ستونها (column) ذخیره میکند. همچنین یک سیستم مدیریت دیتابیسهای NoSQL برای کار کردن با حجم زیادی از دادههای پخش شده میان چندین سرور (که باعث افزایش دسترسیپذیری بدون هیچ گونه عامل خرابی، میشود) است. با زبان Java نوشته شده و توسط Apache توسعه داده شده است.
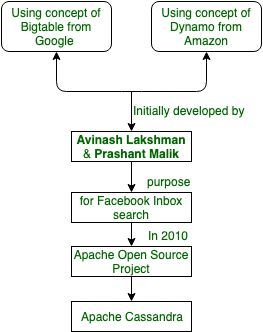
Avinash Lakshman و Prashant Malik در ابتدا Cassandra را در Facebook برای بهبود قابلیت جستوجو صندوق ورودی Facebook، توسعه دادند. Facebook پروژه Cassandra را در جولای ۲۰۰۸، به عنوان یک پروژه متنباز بر روی Google code منتشر کرد. در مارس ۲۰۰۹ به یک پروژه Apache Incubator و در فوریه ۲۰۱۰ به یک پروژه سطح بالا تبدیل شد. این قابلیتهای برجسته Cassandra، باعث معروفتر شدنش شد.
Apache Cassandra برای مدیریت حجم زیادی از ساختار دادههای توزیع شده استفاده میشود. در واقع یک سرویس با ثبات بالا و بدون عاملی که باعث خرابی شود (no single point of failure)، است. لیست زیر، برخی از مزیتهای دیتابیس Apache Cassandra است:
- مقیاسپذیر، دارای قابلیت مدیریت خطا و پایدار است.
- دیتابیسی براساس ستونها (column-oriented) است.
- طراحی توزیع شده آن براساس Dynamo آمازون و مدل دیتای آن براساس Big table گوگل است.
- در Facebook ساخته شده است و به شدت از سیستمهای مدیریت دیتابیسهای رابطهای، متفاوت است.
Cassandra مدل Dynamo-style replication را که هیچ عامل خرابی ندارد را پیاده میکند، اما مدل داده column family قدرتمندتری را به آن اضافه میکند. Cassandra توسط شرکتهای بزرگی نظیر Facebook، Twitter، Cisco، Rackspace، eBay، Netflix و … استفاده میشود.
هدف طراحی Cassandra، مدیریت دادههای حجیم یا Big data، از طریق چندین node یا سرور، بدون هیچ گونه مشکلی است. Cassandra یک سیستم نظیر به نظیر (peer-to-peer) توزیع شده میان nodeهایش دارد و دیتا در میان تمام nodeهای یک کلاستر توزیع شده است.
تمام nodeهای Cassandra که در یک کلاستر قرار دارند، نقش یکسانی را ایفا میکنند. هرکدام از nodeها مستقل هستند، در عین حال به nodeهای دیگر نیز متصل شدهاند. هر کدام از nodeها در یک کلاستر، میتوانند درخواستهای خواندن و نوشتن را، بدون توجه به مکان قرارگیری دیتا در این کلاستر، بپذیرند. هنگامی که یک node از دسترس خارج میشود، درخواستهای خواندن و نوشتن توسط سایر nodeها در شبکه مدیریت میشوند.
آپاچی Apache چیست؟ بررسی ویژگیها، عملکرد و جایگزین آن
آپاچی Apache چیست؟
قابلیتهای دیتابیس Cassandra
Cassandra به دلیل قابلیتهای فنی که ارائه میکند، به سرعت معروف شده است. در زیر به برخی از این قابلیتها میپردازیم:
۱) توزیع پذیری آسان دادهها:
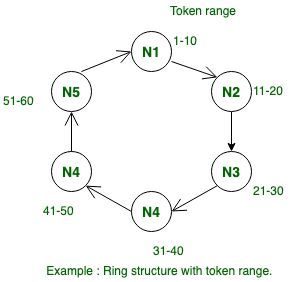
این قابلیت را فراهم میکند که دادهها را در هرجایی که بخواهید، توسط تکثیر آنها در مراکز داده مختلف، توزیع کنید. برای مثال: ۵ node در اختیار داریم، بیایید نامهای آنها را اینگونه تصور کنیم: N1، N2، N3، N4، N5. با استفاده از الگوریتم پارتیشنبندی، محدوده توکن را در نظر میگیریم و براساس این دادهها را توزیع میکنیم. هر کدام از nodeها محدوده توکنی را دارد که دادهها توسط آنها توزیع میشوند (در واقع توکنها در Cassandra، یک مقدار hash هستند که به هنگام افزودن داده به Cassandra ایجاد میشوند و هرکدام از nodeها شامل محدودهای از این توکنها میشوند). برای فهم بهتر به تصویر زیر نگاهی بیندازید:
۲) ذخیرهسازی انواع دادهها:
Cassandra تمام فرمتهای امکانپذیر در دادهها را در خود جای داده است، نظیر ساختار یافته، نیمه ساختار یافته و بدون ساختار. در واقع با توجه به نیاز شما، به صورت پویا، ساختار داده را به ساختار مدنظرتان تغییر میدهد.
۳) مقیاسپذیری:
Cassandra بسیار مقیاسپذیر است و این اجازه را میدهد که بتوانیم سختافزارهای بیشتری برای استفاده مشتریان و ذخیرهسازی دادههای بیشتر، اضافه کنیم.
نحوه نصب وب سرور آپاچی Apache روی سرور مجازی لینوکس Linux یا VPS
نصب وب سرور آپاچی Apache روی سرور مجازی
۴) سرعت بالا در ذخیره سازی:
Cassandra برای اجرا در سختافزارها و یا سرورهای ارزان قیمت و سطح پایین طراحی شده است. Cassandra میتواند به طرز چشمگیری، عملیات نوشتن را با سرعت بالایی اجرا کند، همچنین میتواند صدها ترابایت داده را بدون کاهش سرعت خواندن، ذخیره کند.
۵) قابل اطمینان:
Cassandra عاملی ندارد که باعث خرابی و یا پایین آمدن آن شود، پس میتوان از آن برای برنامههای مهم اقتصادی که در آنها عدم خرابی از اهمیت ویژهای برخوردار است، استفاده کرد.
۶) عملکرد خطی سریع:
Cassandra به صورت خطی مقیاسپذیر است، پس میتوانید عملکرد آن را با افزودن nodeهای بیشتر به کلاستر، افزایش دهید. این قضیه باعث افزایش سرعت پاسخگویی میشود.
۷) پشتیبانی از Transactionها:
Cassandra از خواص ACID (یا Atomicity Consistency Isolation Durability) برای تراکنشها در دیتابیس پشتیبانی میکند.
نحوه دریافت SSL در Apache روی سرور مجازی دبیان
دریافت SSL در Apache
جمع بندی
Apache Cassandra فراتر از یک دیتابیس NoSQL، راهحلی قدرتمند برای مدیریت دادههای حجیم و توزیعشده در مقیاس وسیع است. طراحی بدون گره مرکزی، پشتیبانی از مقیاسپذیری افقی و تحمل خطا، این سیستم را به گزینهای ایدهآل برای سازمانهایی تبدیل کرده که نیاز به زیرساختی پایدار و همیشه در دسترس دارند.
در عصر اپلیکیشنهای دادهمحور و معماریهای توزیعشده، Cassandra انتخابی آیندهنگرانه برای تیمهایی است که به دنبال عملکرد بالا و قابلیت اطمینان در هر شرایطی هستند. اگر حجم دادهها در حال رشد است و پایداری برایتان اولویت دارد، Cassandra میتواند یکی از مطمئنترین انتخابهایتان باشد.
منبع: https://www.geeksforgeeks.org/introduction-to-apache-cassandra
