
آنچه در این مقاله میخوانید
Qdrant چیست؟ آشنایی با دیتابیس برداری و موتور جستجو
۱۱ تیر ۱۴۰۵
خلاصه کنید:



هوش مصنوعی دیگر فقط برای ساخت چتبات یا تولید متن استفاده نمیشود. موتورهای جستجوی هوشمند، سیستمهای پیشنهاد محصول، جستجوی تصویر، دستیارهای مبتنی بر مدلهای زبانی و بسیاری از سرویسهای جدید، همگی باید بتوانند مفهوم دادهها را درک کنند، نه اینکه فقط کلمات یا اعداد یکسان را پیدا کنند. به همین دلیل، روش نگهداری و جستجوی داده نیز تغییر کرده است.
پایگاههای داده رابطهای مانند MySQL یا PostgreSQL برای نگهداری دادههای ساختیافته انتخاب مناسبی هستند، اما زمانی که قرار باشد شباهت معنایی بین متن، تصویر، صدا یا هر نوع داده دیگری بررسی شود، عملکرد آنها محدود است. در چنین شرایطی، پایگاههای داده برداری (Vector Database) مانند Qdrant وارد عمل میشوند. این دسته از پایگاههای داده، دادهها را بهصورت بردارهای عددی ذخیره میکنند و قادرند نزدیکترین نتیجه را از نظر مفهوم پیدا کنند؛ حتی اگر عبارت جستجو شده دقیقا با داده ذخیرهشده یکسان نباشد.
در ادامه میخوانید:
- Qdrant چیست؟
- پایگاه داده برداری یا Vector Database چیست؟
- نمای کلی سطح بالا از معماری Qdrant
- Qdrant چه کاربردهایی دارد؟
- مزایای استفاده از Qdrant
- تفاوت Qdrant با پایگاههای داده سنتی
- چگونه از Qdrant استفاده کنیم؟
- بهترین ارائه دهنده هاست Qdrant
- جمعبندی
- سوالات متداول

Qdrant چیست؟
Qdrant یک دیتابیس برداری (Vector Database) متنباز است که برای ذخیره و جستجوی بردارهای عددی با ابعاد بالا ساخته شده است. این دیتابیس بهجای جستجوی کلمات یا مقادیر دقیق، میزان شباهت میان بردارها را بررسی میکند. به همین دلیل، در پروژههایی که با هوش مصنوعی، LLMها، جستجوی معنایی و سیستمهای پیشنهاد دهنده سروکار دارند، انتخاب مناسبی است.
فرض کنید در یک فروشگاه اینترنتی عبارت “کفش مناسب دویدن” را جستجو میکنید. ممکن است محصولی با عنوان “کفش رانینگ مردانه” دقیقا همین عبارت را نداشته باشد، اما از نظر مفهوم با درخواست شما مرتبط باشد. Qdrant چنین ارتباطی را تشخیص میدهد و نتایجی را نمایش میدهد که از نظر معنا به جستجوی کاربر نزدیک هستند.
برخلاف پایگاههای داده سنتی که دادهها را در سطرها و ستونها نگهداری میکنند، Qdrant با بردارها (Vectors) کار میکند. این وکتورها در واقع نمایش عددی دادههایی مانند متن، تصویر، فایل صوتی یا ویدئو هستند که توسط مدلهای یادگیری ماشین تولید میشوند. هر بردار نیز میتواند همراه با اطلاعات دیگری مانند شناسه، دستهبندی، برچسب یا هر داده دلخواه دیگری ذخیره شود تا در زمان جستجو، نتایج دقیقتر فیلتر شوند.
Qdrant با زبان Rust توسعه داده شده (qdrant github) و همین موضوع باعث شده سرعت و کارایی بالایی در پردازش حجم زیادی از بردارها داشته باشد. این دیتابیس همچنین از APIهای REST و gRPC و کلاینتهای رسمی برای زبانهایی مانند Python، JavaScript، Go و Java پشتیبانی میکند و بهراحتی با ابزارهایی مانند LangChain و LlamaIndex قابل استفاده است.
از Qdrant در پروژههای مختلفی مانند چتباتهای مبتنی بر هوش مصنوعی، سیستمهای RAG، جستجوی معنایی، پیشنهاد محصول، جستجوی تصویر و بسیاری از برنامههایی که بر پایه Embedding کار میکنند استفاده میشود. اگر قرار باشد دادهها براساس مفهوم آنها جستجو شوند، Qdrant یکی از گزینههایی است که ارزش بررسی دارد.
پایگاه داده برداری یا Vector Database چیست؟
برای اینکه نحوه کار Qdrant را بهتر درک کنیم، ابتدا باید بدانیم پایگاه داده برداری چیست و چه تفاوتی با پایگاههای داده معمولی دارد.
در پایگاههای داده رابطهای مانند MySQL یا PostgreSQL، اطلاعات در قالب جدول ذخیره میشوند و جستجو براساس مقدار ستونها انجام میشود. این روش برای دادههای ساختیافته مانند اطلاعات کاربران، سفارشها یا موجودی کالا بسیار مناسب است، اما موقع جستجوی شباهت بین دادهها، این مدلها خیلی دقیق عمل نمیکنند.
پایگاه داده برداری رویکرد متفاوتی دارد. در این نوع دیتابیس، هر داده ابتدا به یک وکتور یا Embedding(بردار عددی از مفهوم متن) تبدیل میشود. این بردار مجموعهای از اعداد است که ویژگیها و مفهوم داده را در خود نگه میدارد. متن، تصویر، فایل صوتی و حتی ویدئو همگی میتوانند به بردار تبدیل شوند و در دیتابیس ذخیره شوند.
برای مثال، اگر دو جمله زیر را در نظر بگیریم:
- بهترین گوشی برای عکاسی
- موبایل مناسب ثبت تصاویر باکیفیت
ممکن است این دو جمله از نظر کلمات متفاوت باشند، اما مدلهای یادگیری ماشین آنها را به بردارهایی تبدیل میکنند که فاصله کمی از یکدیگر دارند. همین موضوع باعث میشود یک دیتابیس برداری بتواند ارتباط معنایی آنها را تشخیص دهد.
در Qdrant هر بردار به همراه یک شناسه و اطلاعات تکمیلی ذخیره میشود. این اطلاعات تکمیلی که Payload نام دارند، میتوانند شامل مواردی مانند نام محصول، قیمت، دستهبندی، تاریخ انتشار یا هر داده دیگری باشند. به این ترتیب، هنگام جستجو تنها شباهت بردارها بررسی نمیشود و امکان فیلتر کردن نتایج نیز وجود دارد.
بهطور خلاصه، تفاوت اصلی این دو نوع پایگاه داده را میتوان به شکل زیر بیان کرد:
| پایگاه داده رابطهای | پایگاه داده برداری |
|---|---|
| جستجو براساس مقدار دقیق داده | جستجو براساس شباهت معنایی |
| مناسب دادههای ساختیافته | مناسب متن، تصویر، صدا و سایر دادههای بدون ساختار |
| نتیجهها براساس تطابق عبارتها | نتیجهها براساس نزدیکترین مفهوم |
به همین دلیل، پایگاههای داده برداری به یکی از اجزای اصلی برنامههایی تبدیل شدهاند که با مدلهای زبانی، جستجوی معنایی، سیستمهای پیشنهاددهنده و سایر کاربردهای هوش مصنوعی سروکار دارند. این دیتابیسها کمک میکنند اطلاعات مرتبط، حتی در صورت تفاوت ظاهری دادهها، با سرعت بالا پیدا شوند.
Vector یا Embedding چیست؟
وکتور(Vector) یا Embedding نمایش عددی یک داده است که توسط مدلهای یادگیری ماشین تولید میشود. این داده میتواند یک متن، تصویر، فایل صوتی یا حتی ویدئو باشد. مدل، محتوای داده را به مجموعهای از اعداد تبدیل میکند؛ اعدادی که مفهوم و ویژگیهای آن داده را در خود نگه میدارند.
برای مثال، جملههای “بهترین لپتاپ برای برنامهنویسی” و “لپتاپ مناسب توسعه نرمافزار” از نظر کلمات با هم تفاوت دارند، اما مفهوم آنها بسیار نزدیک است. زمانی که این دو جمله به Embedding تبدیل شوند، بردارهای حاصل نیز فاصله کمی از یکدیگر خواهند داشت. همین فاصله کم به Qdrant نشان میدهد که این دو عبارت به موضوع مشابهی اشاره میکنند.
نمای کلی سطح بالا از معماری Qdrant

نمودار بالا، نمای کلی از برخی از اجزای اصلی Qdrant را نشان میدهد. در اینجا اصطلاحاتی که بهتر است با آنها آشنا شوید، آورده شده است.
- مجموعهها (Collections): یک مجموعه، مجموعهای نامگذاریشده از نقاط (بردارهایی با بار مفید) است که میتوانید در میان آنها جستجو کنید. بردار هر نقطه در همان مجموعه باید ابعاد یکسانی داشته باشد و با یک معیار واحد مقایسه شود.
- بردارهای نامگذاریشده (Named Vectors): میتوانند برای داشتن چندین بردار در یک نقطه واحد استفاده شوند که هر کدام میتوانند ابعاد و الزامات معیار خاص خود را داشته باشند.
- معیارهای فاصله (Distance Metrics: این معیارها برای اندازهگیری شباهت بین بردارها استفاده میشوند و باید همزمان با ایجاد یک مجموعه انتخاب شوند. انتخاب معیار به نحوهی به دست آوردن بردارها و به ویژه به شبکهی عصبی که برای رمزگذاری پرسوجوهای جدید استفاده خواهد شد، بستگی دارد.
- نقاط (Points) : نقاط، موجودیت مرکزی هستند که Qdrant با آنها کار میکند و شامل یک بردار و یک شناسه و بار داده اختیاری هستند.
- id: یک شناسه منحصر به فرد برای بردارهای شما.
- بردار: نمایش با ابعاد بالا از دادهها، به عنوان مثال، یک تصویر، یک صدا، یک سند، یک ویدیو و غیره.
- بار مفید (Payload) : یک بار مفید یک شیء JSON با دادههای اضافی است که میتوانید به یک بردار اضافه کنید.
- ذخیرهسازی (Storage) : Qdrant میتواند از یکی از دو گزینه برای ذخیرهسازی استفاده کند، ذخیرهسازی درون حافظهای (تمام بردارها را در RAM ذخیره میکند، بالاترین سرعت را دارد زیرا دسترسی به دیسک فقط برای ماندگاری لازم است)، یا ذخیرهسازی Memmap (یک فضای آدرس مجازی مرتبط با فایل روی دیسک ایجاد میکند).
Qdrant چه کاربردهایی دارد؟
Qdrant فقط برای ذخیره بردارها ساخته نشده است. این دیتابیس در پروژههایی استفاده میشود که پیدا کردن نزدیکترین داده از نظر مفهوم، بخش مهمی از کار است. از چتباتهای هوشمند گرفته تا موتورهای جستجو و سیستمهای پیشنهاددهنده، همگی میتوانند از قابلیتهای Qdrant استفاده کنند.
رایجترین کاربردهای Qdrant عبارتاند از:
- جستجوی معنایی (Semantic Search): در جستجوی معمولی، نتیجهها براساس کلمات یکسان نمایش داده میشوند؛ اما در جستجوی معنایی، مفهوم عبارت نیز در نظر گرفته میشود. به همین دلیل، حتی اگر کاربر از واژههای متفاوتی استفاده کند، باز هم نتایج مرتبط نمایش داده میشوند.
- سیستمهای مبتنی بر RAG: در معماری Retrieval-Augmented Generation (RAG)، پیش از اینکه مدل زبانی پاسخ نهایی را تولید کند، اطلاعات موردنیاز از یک منبع داده بازیابی میشود. Qdrant یکی از گزینههای محبوب برای نگهداری Embeddingها و پیدا کردن مرتبطترین اسناد در این معماری است.
- چتباتهای مبتنی بر مدلهای زبانی: اگر قرار باشد یک چتبات به مستندات، مقالات یا اطلاعات داخلی یک شرکت پاسخ دهد، باید ابتدا مرتبطترین محتوا را پیدا کند. Qdrant این مرحله را انجام میدهد و اسناد مناسب را در اختیار مدل زبانی قرار میدهد.
- سیستمهای پیشنهاددهنده (Recommendation Systems): پلتفرمهای فروشگاهی، سرویسهای پخش فیلم و موسیقی یا شبکههای اجتماعی معمولا براساس شباهت بین کاربران و محتوا پیشنهاد ارائه میکنند. Qdrant با جستجوی برداری، پیدا کردن نزدیکترین گزینهها را سادهتر میکند.
- جستجوی تصویر و فایلهای چندرسانهای: بردارها فقط برای متن نیستند. تصاویر، فایلهای صوتی و ویدئوها نیز میتوانند به Embedding تبدیل شوند. در نتیجه، Qdrant قادر است تصاویر یا فایلهای مشابه را بدون نیاز به نام فایل یا برچسبهای از پیش تعیینشده پیدا کند.
- تشخیص محتوای مشابه (Duplicate Detection): در بسیاری از سرویسها لازم است اسناد یا محتواهای تکراری شناسایی شوند. با تبدیل دادهها به بردار و مقایسه آنها، میتوان فایلها یا متنهایی را که شباهت زیادی به یکدیگر دارند، با سرعت بیشتری پیدا کرد.
آشنایی با انواع دیتابیس و کاربرد و اهمیت آن ها
انواع دیتابیس و کاربرد آنها
مزایای استفاده از Qdrant
دلیل محبوبیت Qdrant فقط سرعت جستجوی برداری نیست. این دیتابیس مجموعهای از قابلیتها را در اختیار توسعهدهندگان قرار میدهد که کار با دادههای برداری را سادهتر میکند.
از جمله مهمترین مزایای Qdrant میتوان به موارد زیر اشاره کرد:
- متنباز بودن: کد منبع Qdrant در دسترس است و میتوانید آن را روی زیرساخت خود اجرا یا متناسب با نیاز پروژه از آن استفاده کنید.
- سرعت بالا در جستجوی برداری: Qdrant برای کار با میلیونها بردار طراحی شده و حتی در مجموعهدادههای بزرگ نیز زمان پاسخ مناسبی ارائه میدهد.
- پشتیبانی از فیلترهای پیشرفته: علاوه بر جستجوی برداری، امکان فیلتر کردن نتایج براساس اطلاعات موجود در Payload نیز وجود دارد. این قابلیت در فروشگاههای اینترنتی، سامانههای مدیریت محتوا و بسیاری از پروژههای دیگر کاربرد دارد.
- سازگاری با ابزارهای هوش مصنوعی: Qdrant بهراحتی با ابزارهایی مانند LangChain، LlamaIndex، Haystack و بسیاری از فریمورکهای دیگر قابل استفاده است.
- API و کلاینتهای متنوع: برای زبانهای برنامهنویسی مختلف، کلاینت رسمی ارائه شده است و در صورت نیاز میتوانید از REST API یا gRPC نیز استفاده کنید.
- امکان اجرا روی زیرساخت دلخواه: Qdrant را میتوان روی یک سرور محلی، ماشین مجازی، Docker، Kubernetes یا سرویسهای ابری اجرا کرد.
همین ویژگیها باعث شده Qdrant برای پروژههای کوچک و همچنین سرویسهایی که حجم زیادی از دادههای برداری را مدیریت میکنند، انتخاب قابل اعتمادی باشد.
تفاوت Qdrant با پایگاه های داده سنتی
پایگاههای داده رابطهای مانند MySQL و PostgreSQL سالهاست برای ذخیره اطلاعات ساختیافته استفاده میشوند. اگر قرار باشد اطلاعات کاربران، سفارشها، تراکنشها یا موجودی کالا را مدیریت کنید، این دیتابیسها انتخاب مناسبی هستند. اما زمانی که هدف، پیدا کردن دادههای مشابه باشد، روش کار آنها با Qdrant تفاوت دارد.
| پایگاههای داده رابطهای | Qdrant |
|---|---|
| دادهها در قالب جدول ذخیره میشوند. | دادهها بهصورت بردار ذخیره میشوند. |
| جستجو براساس مقدار دقیق داده انجام میشود. | جستجو براساس شباهت معنایی انجام میشود. |
| برای دادههای ساختیافته مناسب هستند. | برای متن، تصویر، صدا و سایر دادههای بدون ساختار مناسب است. |
| برای جستجوی شباهت به ابزارهای جانبی نیاز دارند. | جستجوی برداری از قابلیتهای اصلی آن است. |
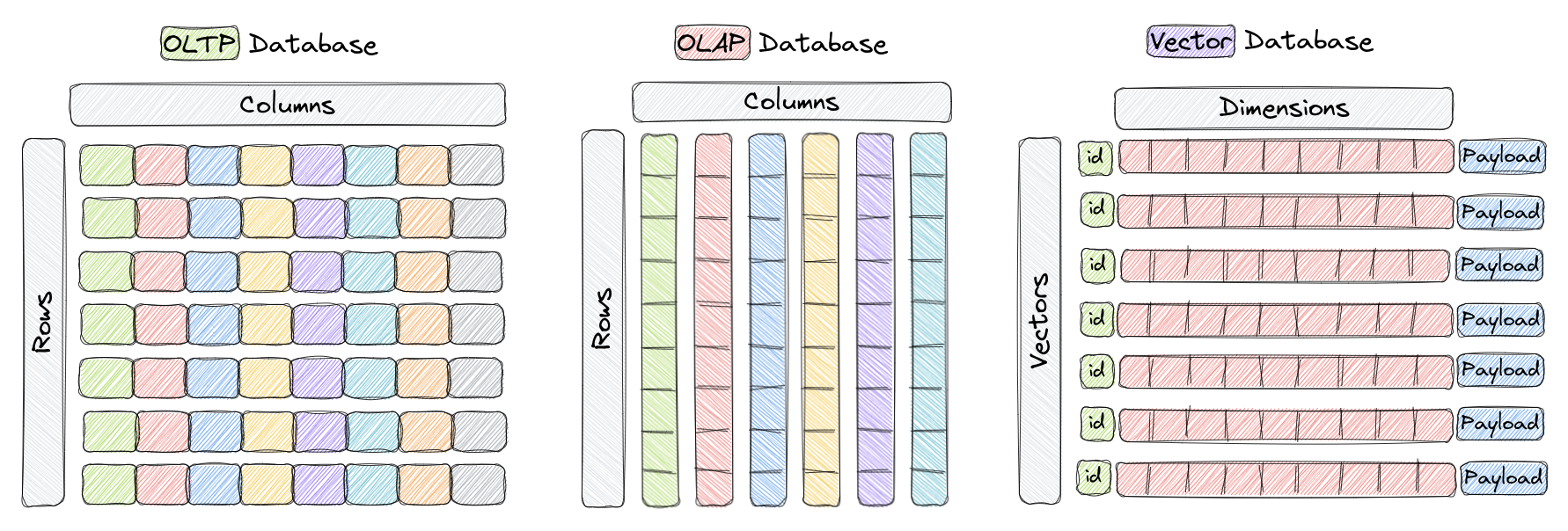
در پایگاههای داده سنتی OLTP و OLAP (همانطور که در تصویر بالا مشاهده میشود)، دادهها در جدولها سازماندهی میشوند و پرسوجوها بر اساس مقادیر موجود در آن ستونها انجام میشوند. با این حال، در برنامههای خاصی از جمله تشخیص تصویر، پردازش زبان طبیعی و سیستمهای توصیهگر، دادهها اغلب به صورت بردارهایی در فضایی با ابعاد بالا نمایش داده میشوند و این بردارها، به علاوه یک شناسه و یک بار مفید را یک نقطه مینامیم. این نقاط عناصری هستند که ما در چیزی به نام مجموعه (Collection) در یک پایگاه داده برداری مانند Qdrant ذخیره میکنیم.
البته این تفاوت به این معنا نیست که Qdrant جایگزین پایگاههای داده رابطهای است. در بسیاری از پروژهها، این دو در کنار یکدیگر استفاده میشوند. برای نمونه، اطلاعات کاربران، سفارشها و پرداختها در یک دیتابیس رابطهای ذخیره میشود، اما Embeddingها و جستجوی معنایی به Qdrant سپرده میشود.
به همین دلیل، Qdrant را بهتر است مکمل پایگاههای داده سنتی بدانیم، نه جایگزین آنها. هرکدام برای نوع خاصی از داده و شیوه جستجو طراحی شدهاند و در کنار هم میتوانند نیازهای یک پروژه را بهخوبی پوشش دهند.
چگونه از Qdrant استفاده کنیم؟
Qdrant را میتوان به روشهای مختلف اجرا کرد. انتخاب هر روش به اندازه پروژه، محل نگهداری دادهها و نحوه استقرار سرویس بستگی دارد.
نسخه ابری (Cloud): اگر میخواهید بدون نصب و مدیریت سرور کار را شروع کنید، نسخه ابری Qdrant انتخاب مناسبی است. پس از ایجاد یک کلاستر، میتوانید از طریق API یا کلاینتهای رسمی، بردارهای خود را ذخیره و جستجو کنید.
نصب روی سرور اختصاصی: بسیاری از تیمها ترجیح میدهند Qdrant را روی سرور یا زیرساخت خود اجرا کنند. این روش کنترل بیشتری روی دادهها و تنظیمات سرویس در اختیار شما قرار میدهد و با Docker و Kubernetes نیز سازگار است.
راهاندازی با برنامههای آماده (One Click Apps): اگر نمیخواهید زمان خود را صرف نصب، پیکربندی و نگهداری سرویس کنید، استفاده از نسخههای آماده سادهترین گزینه است. در این روش، تنها با چند کلیک یک نمونه آماده از Qdrant در اختیار شما قرار میگیرد و میتوانید مستقیما کار با API و ذخیرهسازی Embeddingها را آغاز کنید.
بهترین ارائهدهنده هاست Qdrant
لیارا به عنوان یکی از ارائهدهندگان خدمات ابری، مجموعهای از برنامههای آماده (One Click Apps) را در اختیار کاربران قرار میدهد که با استفاده از آنها میتوانند تنها با چند کلیک، نرمافزارهای متنباز مختلف را راهاندازی کنند.
یکی از این برنامههای آماده، دیتابیس برداری Qdrant است که کاربران میتوانند بهراحتی آن را از طریق لیارا تهیه کرده و روی پلتفرم ابری خود مستقر کنند. راهاندازی این سرویس کاملاً خودکار انجام میشود و نیازی به تنظیمات پیچیده ندارد. با استفاده از Qdrant، میتوانید دادههای برداری (Embedding) را ذخیره کنید، جستجوی معنایی انجام دهید و زیرساخت لازم برای سیستمهایی مثل RAG، چتباتهای هوشمند و موتورهای جستجوی مبتنی بر مفهوم را بهسادگی پیادهسازی کنید.
این ابزار با APIهای قدرتمند و پشتیبانی از کلاینتهای مختلف، مدیریت دادههای برداری را برای تیمهای توسعه آسانتر میکند و امکان اتصال سریع به فریمورکهایی مثل LangChain و LlamaIndex را فراهم میسازد.
برای آشنایی بیشتر با نحوه استفاده از این سرویس، میتوانید به مستندات سایت لیارا مراجعه کنید.
با برنامه آماده Qdrant لیارا، زیرساخت جستجوی برداری خود را سریع راهاندازی کنید.
✅ راهاندازی سریع✅ بدون نیاز به تنظیمات پیچیده✅ مناسب برای RAG
خرید و راهاندازی Qdrant لیارا
جمع بندی
با رشد مدلهای زبانی و جستجوی معنایی، نیاز به ابزارهایی که دادهها را بر اساس مفهوم جستجو کنند بیشتر شده است. Qdrant یک دیتابیس برداری متنباز است که امکان ذخیره و جستجوی سریع میلیونها بردار را فراهم میکند.
در این مقاله با مفاهیم پایه پایگاه داده برداری، نحوه کار Qdrant، کاربردها و روشهای راهاندازی آن آشنا شدیم. اگر در حال ساخت سیستمهایی مثل RAG، چتبات یا موتور جستجوی معنایی هستید، Qdrant گزینه مناسبی برای مدیریت دادههای برداری است.
برای شروع سریعتر هم میتوانید از برنامه آماده Qdrant لیارا استفاده کنید تا بدون درگیر شدن با نصب و تنظیمات، مستقیم وارد توسعه شوید.
سوالات متداول
آیا برای استفاده از Qdrant حتما باید مدل Embedding ساخت؟
خیر. Qdrant خودش مدل تولید Embedding ندارد. برای تبدیل دادهها به بردار باید از مدلهای جداگانه مثل OpenAI یا مدلهای متنباز استفاده شود و بعد خروجی به Qdrant ارسال شود.
آیا Qdrant برای پروژه های کوچک هم مناسب است؟
بله. میشود از آن برای پروژههای کوچک هم استفاده کرد، اگر هدف تست جستجوی معنایی یا ساخت نمونه اولیه باشد. ساختار آن طوری طراحی شده که از پروژههای سبک تا سیستمهای بزرگ را پوشش دهد.
آیا میشود Qdrant را بدون سرور جدا اجرا کرد؟
بله. امکان اجرای محلی با Docker وجود دارد. این روش بیشتر برای توسعه و تست استفاده میشود و نیاز به زیرساخت پیچیده ندارد.
Qdrant فقط برای هوش مصنوعی استفاده می شود؟
خیر. تمرکز اصلی آن روی دادههای برداری است، اما در عمل بیشتر در پروژههای هوش مصنوعی استفاده میشود چون این نوع دادهها معمولا از مدلهای یادگیری ماشین تولید میشوند.
آیا می توان Qdrant را با ابزارهای دیگر ترکیب کرد؟
بله. Qdrant معمولا در کنار ابزارهایی مثل LangChain، LlamaIndex یا سیستمهای بکاند استفاده میشود و بهراحتی با API به آنها وصل میشود.
